
Grammatical Rules for DNA Sequence Representation

In this article, you will learn how to write DNA sequences, and become familiar with the conventions that are used for its representation.
DNA (deoxyribonucleic acid) and RNA (ribonucleic acid) are the two types of molecule known to record and pass on heritable genetic information from one generation to the next. The use of RNA for this purpose is limited to a family of viruses called RNA viruses – the rest of the known biological organisms use DNA to store and to transmit genetic information. With a few exceptions (which include gametes, certain immune cells, and tumour cells), the DNA content of all of the cells in an organism is identical.
The information encoded in DNA forms the genetic blueprint for the production of proteins and other important components of the cellular machinery. Structurally it forms a large sequence of nucleotides attached covalently to each other, forming a backbone of deoxyribose (sugar) rings and phosphate groups to which bases are attached, as shown in the DNA diagram below. There are three bases that are found in DNA and RNA: adenine, cytosine and guanine. Thymine is found exclusively in DNA, and is replaced by uracil exclusively in RNA.
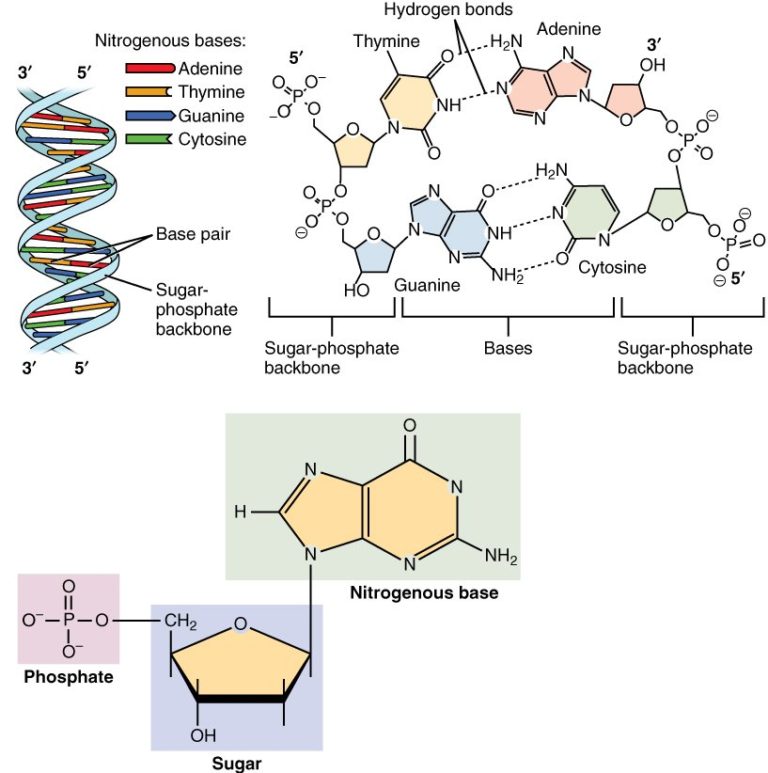
DNA Diagram
Acknowledgement https://en.wikipedia.org/wiki/Nucleotide#/media/File:0322_DNA_Nucleotides.jpg image
For simplicity, each nucleotide is represented by just one letter: Adenine (A), Cytosine (C), Guanine (G), Thymine (T) and Uracil (U). If the nucleotide is unknown, it is represented with the letter “N”. An extended list of one-letter representations of different ambiguity codes for nucleotides can be found in the IUPAC list
Genomic DNA is double-stranded. This means that for each strand of DNA with a given sequence, there is an opposite strand that contains the complementary sequence where A complements T and G complements C. This complementarity is called the “Watson-Crick pairing rule” in honour of the two researchers who published the first paper describing the base-pairing found in the structure of DNA.
When representing both strands of the DNA molecule, we need to write both the forward and reverse strands, following the Watson-Crick rule of A=T and G=C.
5’-ATGCGATCGGACAGTCGAGTCCAGTAGACGATC-3’ forward strand 3’-TACGCTAGCCTGTCAGCTCAGGTCATCTGCTAG-5’ reverse strand
In this example, the second sequence shown is the reverse strand and is the complement of the forward strand. Notice that in addition to the nucleotide sequence, we find the numbers 5’ and 3’ (we call then five-prime and three-prime) at the start and end of each of the strands. The forward strand is written in the 5’-3’ orientation, whereas the reverse of complementary strand is written in the 3’->5’ orientation. This represents the way these two molecules would be seen in a DNA fragment. These numbers are not arbitrary; they represent the carbons in the chemical structure of the sugar ring of the nucleotide which are involved in the chemical reactions that build the DNA phosphate-sugar backbone. In vivo, DNA synthesis occurs by adding free nucleotides via their 5’ end to the 3’ end of a nascent DNA molecule. This produces directionality (enzymes can only synthesise DNA in the 5’ to 3’ direction) which researchers have adopted as a convention for writing nucleic acids sequences. This means that unless otherwise stated, all nucleic acid sequences are written in the 5’ to 3’ direction.
Despite being a double helix of complementary DNA sequences, DNA is almost always represented as a single sequence.
5’-ATGCGATCGGACAGTCGAGTCCAGTAGACGATC-3’
And as we saw before, the 5’->3’ is a convention that all researchers in genetics follow, and therefore we do not need to specify it any longer. We can simply write our example sequence as:
ATGCGATCGGACAGTCGAGTCCAGTAGACGATC
Bacterial Genomes I: From DNA to Protein Function Using Bioinformatics


Bacterial Genomes I: From DNA to Protein Function Using Bioinformatics
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




