
Setting up the RHadoop working place

Introduction
With this article we will guide you through the process of setting up your RHadoop working place. We are assuming that (i) you already have the latest version of VirtuaBox and (ii) you have successfully downloaded our mint_hadoop virtual machine, where the RHadoop environment is prearranged.
Virtual machine
First, we search on our computer for the virtual box and run it. In the VirtualBox we find our virtual machine called mint_hadoop and run it. If you receive any notification about the keyboard or mouse, we suggest that you ignore it.
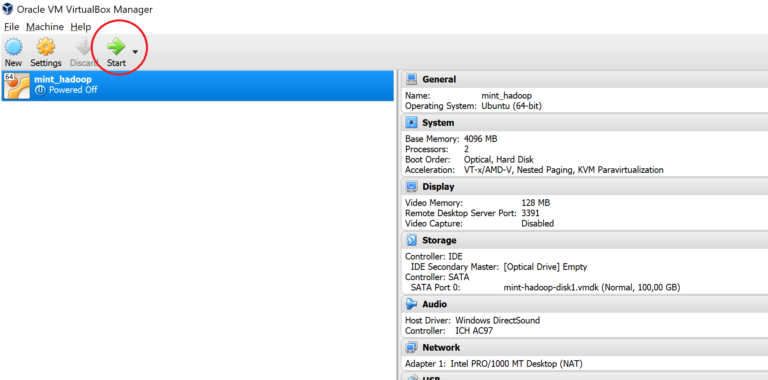
We log in as hduser with the password ‘’hadoop’’. We can see a welcome screen, which we can also close.
Hadoop
First, we start the terminal window. We run Hadoop with two commands:
start-dfs.shis used to run theHadoopdistributed file system. This establishes one namenode and the related datanodes – in our case only one datanode.
- Next we run
start-yarn.shto start the master and node resource managers and map reduce.
R
We need to run R, which we will use to create and submit the map-reduce tasks to Hadoop. We decided to use RStudio, which is a free and open-source, integrated development environment for R. We run R through RStudio from the terminal window using the command rstudio &:

Note that if running the script rstudio reports some warnings, then they are probably related to missing fonts. We ignore them and just press enter.
RHadoop
Now we set up RStudio for the data analysis with RHadoop. We open a new script file and save it to a local folder. At the beginning, we must set the system environment for Hadoop. These lines:
Sys.setenv(HADOOP_OPTS="-Djava.library.path=/usr/local/hadoop/lib/native")
Sys.setenv(HADOOP_HOME="/usr/local/hadoop")
Sys.setenv(HADOOP_CMD="/usr/local/hadoop/bin/hadoop")
Sys.setenv(HADOOP_STREAMING="/usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar")
Sys.setenv(JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64")
define the system variables. We copy them into the script file, mark them and execute them by pressing ctrl+enter.
Finally, we load the basic RHadoop libraries.
We establish our connectivity to the Hadoop Distributed File System by loading the library rhdfs.
library(rhdfs)
To perform a statistical analysis in R with Hadoop MapReduce we also need to load library rmr2, where the scripts for the map-and-reduce operation are defined:
library(rmr2)
We close this last step with the execution of hdfs.init():
hdfs.init()
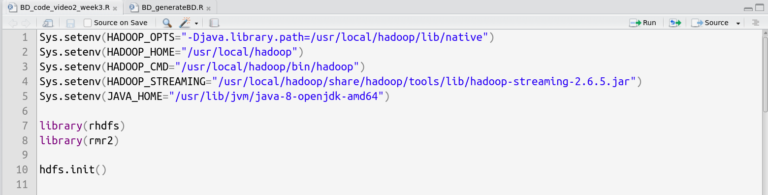
Now RHadoop is ready and we can start writing scripts for the big-data analysis.
Closing the working place
When we want to close the RHadoop session we:
- Save all the script files and if needed also the workspace;
- Close
RStudioby clicking the close button; - Stop
Hadoopby typingstop-yarn.shandstop-dfs.shand - Stop the terminal window and the
mint_hadoopvirtual machine by clicking the close button.


Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




