
Game theory

Robots of the future will need to work in teams to accomplish tasks. However, effective teamwork will require coordination among the robots – game theory is one way to provide coordination. This step introduces the basics of game theory.
Game theory for robot teams
Advances in control and automation have made it possible for robot teams to work together in order to complete a task. When robots work together in such as way, the action of each robot in the team influences the actions of the other robots. Therefore, if the robots need to work independently, a coordination mechanism among the robots is needed. Game theory provides such a mechanism.
Game theory: In game theory, each robot is considered to be a player of a game and receives rewards dependent on the actions of the whole robotic team.
Reward: A reward is a stimulus used to indicate a desired outcome has been achieved. A reward for humans is context-dependent, e.g. a gold medal for winning a race, but for robots is usually arbitrary, e.g. a 0 for no reward, or a 1 for a reward.
A simple game for two unmanned air vehicles
- One UAV is modelled as a ‘row player’ and the other is a ‘column player’.
- If both UAVs fail to coordinate by choosing to fly at the same altitude, they will not receive any reward (i.e. 0).
- Each UAV receives a positive reward (i.e. 1) if they avoid collision by flying at different altitudes.
| Column Player | |||
|---|---|---|---|
| Fly at high altitude | Fly at low altitude | ||
| Row Player | Fly at high altitude | 0,0 | 1,1 |
| Fly at low altitude | 1,1 | 0,0 |
Nash equilibrium. A Nash equilibrium is a solution to a non-cooperative game where each player, knowing the playing strategies of their opponents, have no incentive to change their own strategy.
Example: In the UAV example above, once the UAVs are in a Nash equilibrium with reward 1,1 (representing one UAV flying high, one UAV flying low, and both avoiding a collision), if one UAV changes altitude, this will result in a collision – i.e. the UAV would be worse off by changing strategy.
Learning algorithms in game theory
Game-theoretic learning algorithms can be used as a coordination mechanism among the robots. These are iterative processes where the same game is repeatedly played until either coordination is achieved or the maximum number of iterations is reached.
The learning algorithm follows an iterative procedure – at each iteration, each robot:
- Computes a strategy on how to choose an action
- Selects the best action according to the strategy
- Checks if coordination is successfully established amongst the joint action of the team
a) If no, a new iteration starts at step 1 and each robot adjusts and updates their strategy
b) If yes, the learning algorithm terminates.
The general procedure of game-theoretic learning algorithms can be represented by the following figure.
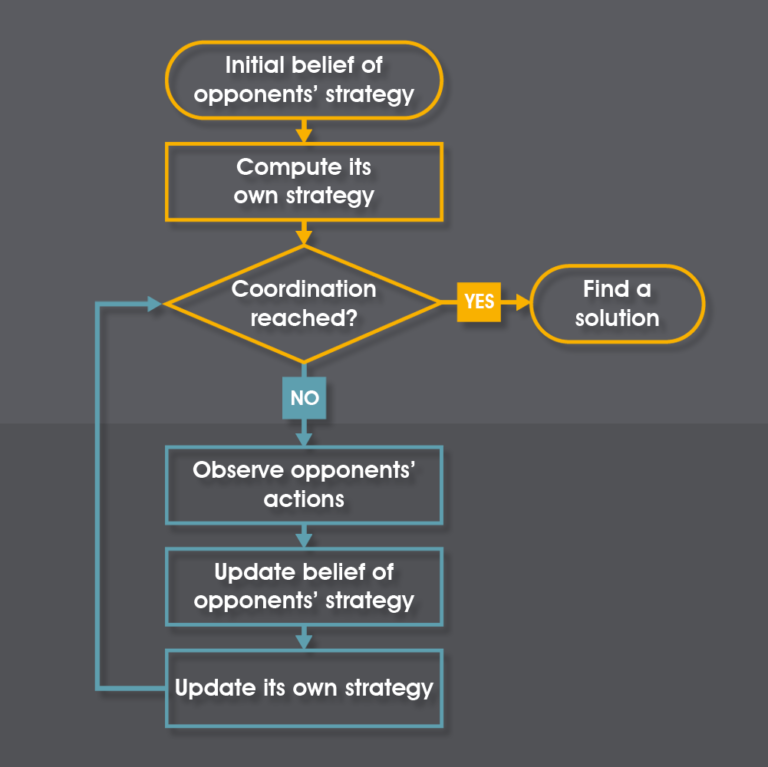
The basic principle behind these algorithms is that robots use the history of observed actions in order to predict the other robots’ strategy and then choose an action based on their prediction. The key result is that robots successfully learn to play the game.


Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




