
Duplicate Detection
As users are creating records, they may not be aware that the record they are creating already exists in the system.
This step will guide us through the out-of-the-box duplicate detection functionality, designed to alert the user to potential duplicates when they create or update records interactively in model-driven apps.
Duplicate detection is a commonly requested feature in database applications to help keep data clean. As users are creating records, they may not be aware that the record they are creating already exists in the system.
The out of the box duplicate detection functionality is designed to alert the user to potential duplicates when they create or update records interactively in model-driven apps. They can also be run as a system job in the background to find potential duplicates for the administrator to review.
Additionally, developers can detect duplicates when using the platform API via code. These scenarios are all enabled by enabling duplicate detection and configuring the rules on what is to consider a duplicate.
Duplicate Detection Settings
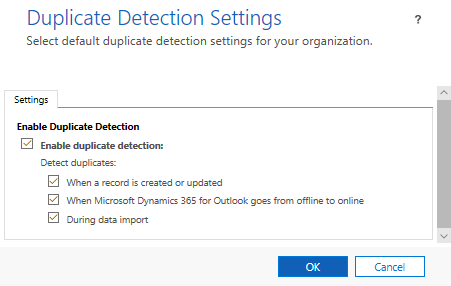
Before duplicate detection can be used it must be properly enabled. To do this, navigate to the data management area of settings and open duplicate detection settings to ensure that duplicate detection is enabled for the organisation.
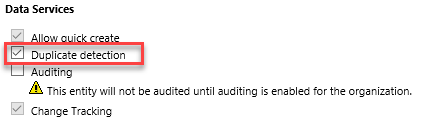
Any entity for which you would like to use duplicate detection needs to be enabled at an entity level. The data services area of the entity is found in any solution where the entity is present.
Once the organisation and specific entities are enabled, duplicate detection rules can be created.
Duplicate Detection Rules
Duplicate detection rules state which fields will be used to determine potential duplicate data. This is usually determined by the most unique data on the record, such as an email address.
Often multiple lines are used to help rule out false positives, such as first name, last name and business phone in the same rule.
Fields can be an exact match, share a given number of first letters or last letters. For example, you may have account names where the first six letters are a match, and this might need to be reviewed to see if the new account is a child of an existing account.
You can decide if you want to force your matches to be case-sensitive. Typically, this box is left unchecked. You can also choose to ignore blank values. Ignoring blank values prevents the rule from seeing the specified field as blank on two records as a match.
Typically, this checkbox is checked, and blanks are ignored. It is common to check the box to exclude inactive records from the rule, so that previously resolved duplicates do not keep popping up in the results.
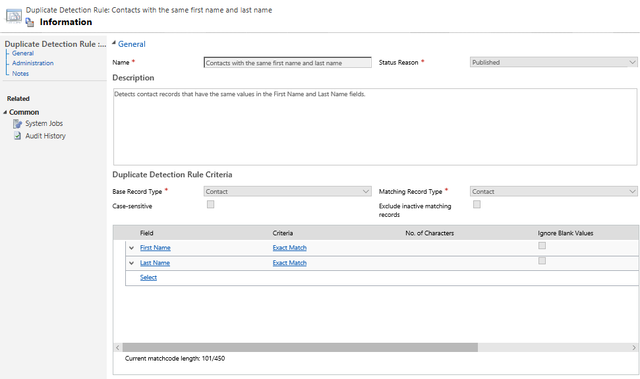
Duplicate detection can also be used to screen two entities to see if there are duplicates across the records, such as a ‘lead’ that is also a ‘contact’. The matching record type is used to specify which other records should be checked, whether it is the same entity or a different entity.
You can have multiple active duplicate detection rules for an entity.
Duplicate Detection Jobs
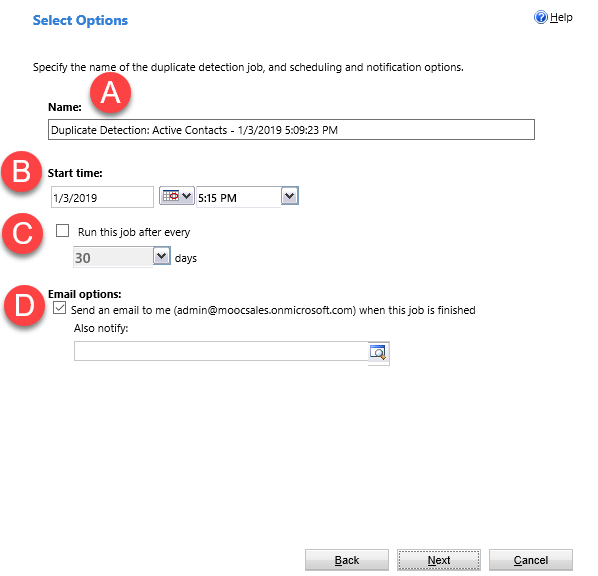
Duplicate detection jobs can be set up as system jobs to run periodically and check for duplicates. Several options are available during the configuration of a duplicate detection job:
-
Enter a name that reflects the criteria of the query.
-
A duplicate detection job can run immediately but are commonly scheduled to run after hours to not impact user productivity.
-
By checking this box and selecting a frequency the duplicate detection job will run automatically in the future.
-
Duplicate detection jobs can send an email to the administrator and another email address after the job is complete.
After the duplicate detection job has run, an administrative user such as the system administrator should open the duplicate detection system job and review and address the potential duplicates.
Considerations
-
Duplicates aren’t detected when a user merges two records, activates or deactivates a record, or saves a completed activity.
-
If the duplicate detection rule contains only one condition, blank values are ignored during the duplicate detection job.
-
The out of the box duplicate detection functionality is very literal and not strict enough for all environments. The functionality will suggest possible duplicates but is not restrictive for users and does not enforce a rigorous duplicate protection policy. In some implementations, it is necessary to bring in a third-party solution or custom developer logic for managing duplicates.
In the next step you’ll have the ‘Duplicate Detection’ Hands-on Lab for this week where you’ll be tasked with configuring duplicate detection rules, as per the needs set forth in the brief
Dynamics 365: Implementing Power Platform Integrations


Dynamics 365: Implementing Power Platform Integrations
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




