
Boolean indexing
Combining all the concepts we have learnt so far (ie, vectorisation, indexing, and slicing), we can program some very complex and powerful filtering logics in a single Python statement.
One of these operations is called boolean indexing, and this is very widely used in data wrangling aspects of data analysis.
Let’s use an example scenario to explain:
- A sequence consisting of the name of all the customers, in order, whenever they have made a purchase (ie, a customer can appear more than once in the list).
- Another sequence consisting of the details of each transaction for the specific customer in order.
- The sequence is stored in the NumPy Arrays, and now we want to select the transactions for a particular customer.
We can solve the above scenario using a combination of vectorisation, indexing, and slicing.
The code snippets simulate this scenario with steps to follow.
Step 1: Create data
To apply the boolean filters, you need to have dummy data. Let us create one for this activity.
Code:
customers = np.array(['Bob', 'John', 'Miller', 'Bob', 'Sammy', 'Samuel', 'Tony', 'Amanda', 'Bob'])
customers.ndim, customers.shape
Output:
(1, (9,))
Step 2: Apply comparison operator to create a boolean filter
As operations on NumPy Arrays are vectorised, if we apply a comparison operator, the resultant Array will be a boolean Array with True or False values in it, depending on the filter.
Let’s perform the operation customer name = ‘Bob’ and see what happens.
Code:
data = np.random.randint(1,100, size=(9,4))
transactions = np.array(data)
transactions
Output:
array([[77, 41, 66, 61],
[42, 29, 35, 7],
[48, 93, 62, 77],
[27, 54, 3, 31],
[ 2, 71, 64, 57],
[96, 13, 8, 63],
[10, 62, 54, 3],
[ 7, 83, 17, 72],
[13, 58, 30, 50]])
Step 3: Pass boolean filter for the slicing of the Array
Here, we can pass this boolean filter as one of the index parameters in the slicing operations.
We want to select all the transaction rows related to customer ‘Bob’, and we want to select all the columns for those selected rows. So, we will pass the following slicing parameter:
- boolean filter – for row index
- : – for the column index (ie, picking all columns)
The code snippet shows this behaviour and you will see rows 1, 3, and 9 are filtered. Just for the ease of viewing the result, the value 1,000,000 (1.0e+6) is also broadcast for these elements.
Code:
customers == 'Bob'
Output:
array([ True, False, False, True, False, False, False, False, True])
Code:
slice = transactions[customers=='Bob', :]
slice
Output:
array([[77, 41, 66, 61],
[27, 54, 3, 31],
[13, 58, 30, 50]])
Code:
transactions[customers=='Bob', :] = 1000000
transactions
Output:
array([[1000000, 1000000, 1000000, 1000000],
[ 42, 29, 35, 7],
[ 48, 93, 62, 77],
[1000000, 1000000, 1000000, 1000000],
[ 2, 71, 64, 57],
[ 96, 13, 8, 63],
[ 10, 62, 54, 3],
[ 7, 83, 17, 72],
[1000000, 1000000, 1000000, 1000000]])
Now it should be clear for you why Boolean indexing is the efficient way of filtering rows in a NumPy Array based on certain selection criteria dependent on the requirements.
Transposing Arrays
Generally, transposing Arrays is a widely used internal operation in various machine learning and deep learning algorithms. Transposing operations on Arrays will convert rows into columns, and columns into rows.
The diagram shows how this operation works.
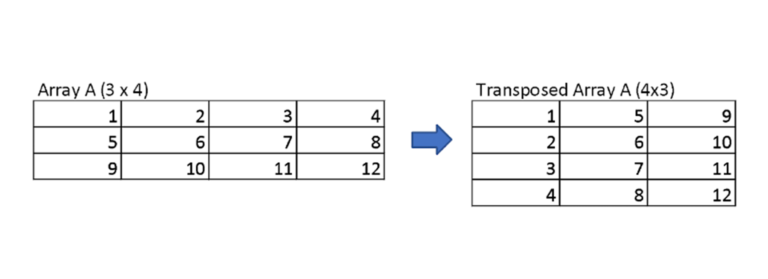
Transposing is a special type of reshaping that returns a view on the underlying NumPy Array data without copying anything. For this purpose, there is a special attribute, T, available for every NumPy Array.
The code snippet shows its usage:
Code:
arr = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
arr
Output:
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
Code:
arr.T
Code:
array([[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11],
[ 4, 8, 12]])
Python Packages: NumPy and Pandas Dataframe


Python Packages: NumPy and Pandas Dataframe
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




