
What can you do with GANs?

Here, we give you some GAN results and give examples of some of the things we can do with a GAN.
Random face synthesis
Once a GAN is trained, we only need to use the generator. We simply generate a random latent vector, pass this as input to the generator network and get an image as output. The following random faces were produced by a GAN trained on face images using the state-of-the-art StyleGAN2 architecture:

The images are remarkable in their detail, diversity and photorealism. Note that the GAN learns plausible background synthesis that is consistent with the lighting on the face. It also learns depth of field effects where the background is blurred (the network was trained on portrait photos from flickr where this effect is common).
Although these results are very impressive, the GAN is not perfect. Let’s see some examples of failure cases.
Failure cases

In this image, notice that the left earring is distorted and that it isn’t consistent with the right one. Earrings are hard because they are highly variable and only seen in some training images. Also, they create a long range dependence – pixels far away from each other are very highly correlated in terms of small details. Convolutional architectures are bad at capturing this sort of relationship.

This image is very good except for the right shoulder. The collar is correctly synthesised but where the rest of the clothing should be, there is a strange mix with the background. Again, this is because clothing is highly variable and there are not enough training examples in the dataset to learn all possible clothing styles and relationships.
Both these artefacts would be partially addressed by simply using more (and more diverse) training data.
Latent space visualisation
Now we get to a fun part. The latent space gives us a way to control face images. If we move a small distance in the latent space, the image changes by a small amount. This means we can get smooth transitions between faces. In this animation, we are talking a random walk around the latent space and visualising the output. Note that most of the faces along the path are plausible and realistic.
Latent space editing
Now we can do some really cool stuff! We can do machine learning within the latent space. If our images are labelled with attributes like whether someone is wearing glasses or whether they have a beard, we can train networks to manipulate a latent vector to add these attributes. So, we can take an image of a real person, find the latent vector that gives the image that best matches the real image and then manipulate the latent vector. This gives us a way to do photorealistic image editing. Let’s see some examples.
Here is a real image of a face:

Now, we reconstruct the image by finding the latent code that gives an image that best matches this one. Then we manipulate the latent code, in this case to adjust the pose attribute:
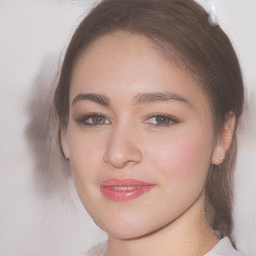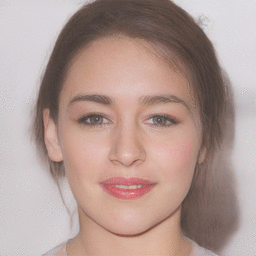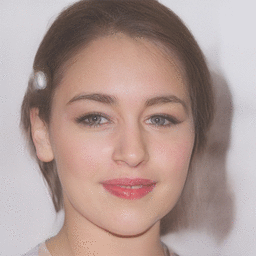
Here’s another real face:

We repeat the same process, but this time we edit age to younger:

and older:

If we gradually move between the young and old result we can see a simulation of aging:

Finally, let’s try adding glasses:

You may notice in this result that the addition of glasses also causes the hair to change. This is an undesired result of machine learning based image synthesis. Since the whole system is a black box, we have no obvious way to control behaviour of the system when it does something we don’t like. The only option would be to add lots more training data of people wearing glasses with different hairstyles so we don’t learn this spurious correlation. Clearly, this isn’t viable for every possible edit we might want to make.
Nevertheless, it’s clear that GANs provide a hugely powerful method for synthesising realistic image content.
Reflections
GANs have introduced us to a few new concepts. Firstly, they involve a generative model as opposed to the discriminative models we’ve seen CNNs used for. Secondly, they are an unsupervised learning technique. All we provided was a set of images, we did not have any labels. This is a very interesting area of machine learning where we can learn representations of data just from the data itself. This a hot topic for research.
References
Karras, Tero, et al. “Analyzing and improving the image quality of stylegan.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Intelligent Systems: An Introduction to Deep Learning and Autonomous Systems


Intelligent Systems: An Introduction to Deep Learning and Autonomous Systems
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




