
Garbage in/Garbage out: importance of generating good data and cleaning up

Taking data and proceeding with analysis without first cleaning your data (also known as data wrangling) or without doing the necessary quality control can lead to inaccurate or even totally misleading conclusions.
Data wrangling includes correcting incomplete, inaccurate, irrelevant, corrupt or incorrectly formatted data, and finally organising the data before the core analysis begins.
Ask most data analysts/scientists and they will tell you that data wrangling can take up about 80% of their work. Why spend so much time on just this one task? Well, because your output is only as good as your input data – which is where the acronym “garbage in, garbage out” (GIGO) comes from.
Take a look below at what happens when you don’t consider the consequence of missing values in your data – often encoded as “99” in your data set. In the top image, missing values were not removed. In the bottom image, removing these values results in a graph which demonstrates more clearly the correlation between education and annual income.

Click here to enlarge the image A
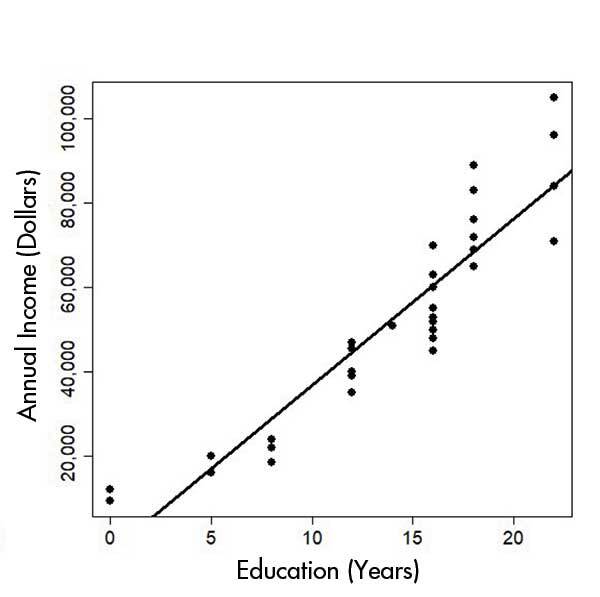
Click here to enlarge the image B
Figure 1 A and B – Building a model without accounting for missing values (top image – A) versus removing missing values (bottom image – B). Source: Chance.
Besides handling missing data, some other data cleaning steps may include filtering unwanted outliers (data values that are very different to the rest of the values). The general rule is to look at your data with and without outliers, and to make sure that the outliers do not take the focus away from the main results or that you use a robust method that can handle outliers.
Standardising your data may also significantly improve your data. For example, if you are comparing SARS-CoV-2 outbreaks on a per-country level, and you are looking at the data from the USA, you would want to include city or state-level data like Chicago and New York under the USA. Similarly, different variations of the country name USA, like America and the US, or misspellings of the country’s name, or even something as simple as matching the case of the word (“usa” versus “USA”), would all need to be fixed.
Other data cleaning efforts include handling low-quality, duplicate and incomplete data and getting rid of unwanted/insecure data. With sequenced data, this may mean removing sequenced reads that are of low quality (Bernasconi, 2021). Removing unwanted data may be similar to a filtering step. For example, you may want to only look at data based on nose swabs, so you would remove data collected from throat swabs. You should also check for insecure data, which may identify a user or an organisation and therefore breaches their privacy.
Sometimes you will just have plain incorrect data due to human error. The person may have just completely misread what was asked for and entered something that does not make sense. For example, they may enter a date in the geographical coordinates field, because they never looked at the column heading, but just saw existing values which looked similar to dates.
Ultimately data cleaning, quality control and curation allow us to more easily explore and understand our models/graphs. And most importantly, it allows us to make more accurate conclusions when observing the outcomes/results. How much of your time is spent on data wrangling? What methods and processes are you using to ensure data quality? Please share your experiences in the discussion area.
Making sense of genomic data: COVID-19 web-based bioinformatics


Making sense of genomic data: COVID-19 web-based bioinformatics
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.





{kind=link}