
Metadata: standardisation and colection tools
Click here to enlarge the image
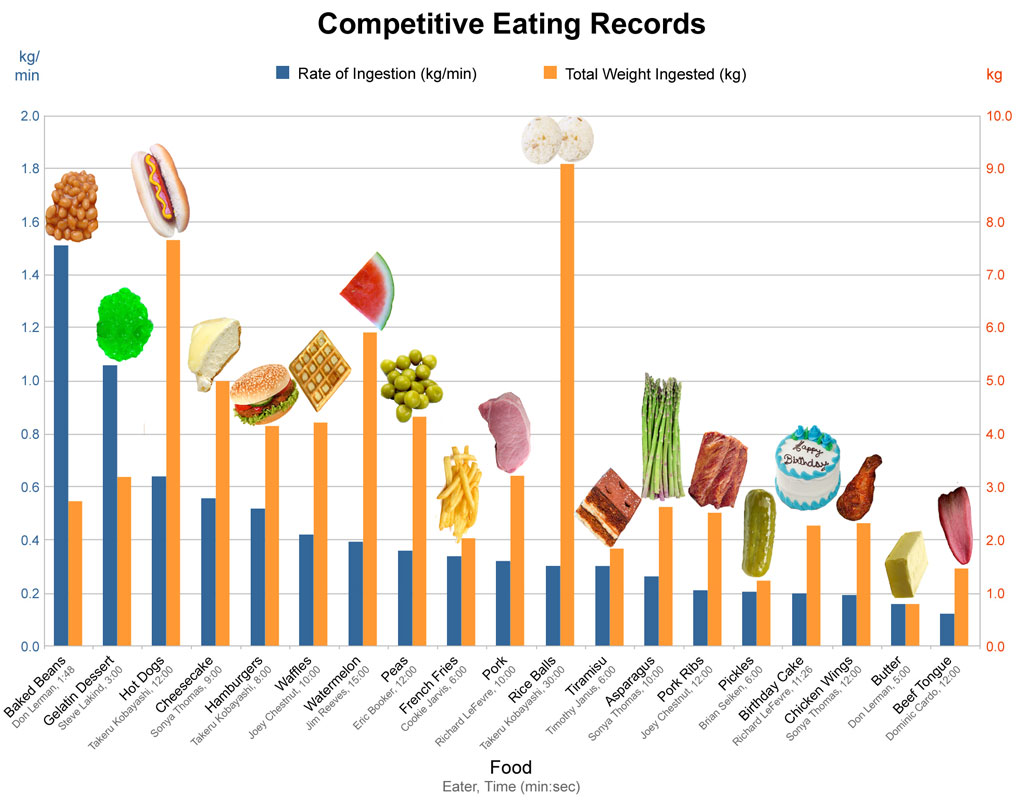
Figure 1 – An interesting-looking graph with incomplete labelling. Source: Hugh Fox III
Imagine coming across this interesting-looking graph in Figure 1 above, but not knowing exactly what it’s trying to show you. The heading which read: “Competitive Eating Records” has been cropped off, and there are missing y axis labels which should have shown that the yellow bars were the total weight in food ingested (kg) and the blue bars were the rate of ingestion (kg/min).
We’ve talked about the “garbage in; garbage out” (GIGO) principle in the context of ensuring good quality data. However, even if you have the best quality data, if your data has no context, you have no story.
So what exactly is metadata, and why is it important?
It is now easier than ever to access millions of sequenced datasets deposited in public databases. This mining of data enables us to do extensive meta-analyses to gain new and unexpected insights into the underlying biological mechanisms across viruses and the tree of life.
However, this process is often hindered by a lack of accompanying metadata. Metadata comprises any data that describes the sample type, collection procedure, extraction, assay methods used, analysis with the chosen parameters, filtering steps, quality control, reporting of software versions, as well as any other phenotypic descriptions.
Most of the time, some metadata is provided during data submissions, but this metadata is often unstandardized. A standardised format implies that there is a checklist which necessitates that a minimum amount of metadata must accompany the data and that free text is limited in favour of a controlled vocabulary.
The COVID-19 pandemic has especially highlighted how necessary it is to have informed data. Metadata such as the time and the place where the samples were collected, which may have not been as important to genomic datasets before, suddenly became crucial. Many repositories such as GEO and ENA now require research teams to use a metadata sheet with compulsory fields that must be populated when submitting data. Extensive efforts have also been made towards both manual curation and the automated assignment of metadata, through natural language processing (NLP) and the use of machine learning models.
Describing the WHO, WHAT, HOW, WHERE, and WHEN of genomic data also contributes to the findable, accessible, interoperable and reproducible (FAIR) guiding principles, to support the reuse of scientific data, and very importantly, it helps to inform public health responses.
Although we acknowledge the importance of accompanying genomic data with the appropriate metadata, we also have to be cognizant of the fact that the collection, anonymisation, storage and access to this data have to be carefully managed in a way that protects the donors. Submitting a data management plan as part of the research plan has therefore become an increasingly standard procedure.
Making sense of genomic data: COVID-19 web-based bioinformatics


Making sense of genomic data: COVID-19 web-based bioinformatics
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.





{kind=link}
{kind=link}