
The GenBank file format

In this article, you will become familiar with another bioinformatic file type – the GenBank file format.
The Genbank format allows for the storage of information in addition to a DNA/protein sequence. It holds much more information than the FASTA format. Formats similar to Genbank have been developed by ENA (EMBL format) and by DDBJ (DDBJ format).
We have already discussed how protein and DNA sequences are represented in a way that allows us to save this sequence in a computer file for later reference or manipulation. We are now going to investigate how additional information about a sequence can be stored in a systematic and controlled way. The purpose of this highly organised way of providing additional data is to make it possible for this information to be standardised for human interpretation, and to be handled by many different computer programmes.
The previously-discussed FASTA format is probably the simplest of all sequence data file formats. Although we can add some text in its header (first lane indicated by “>”), in some cases it might be necessary to add more information. Moreover, this information might need to be categorised to allow for its differentiation; for example, to discriminate a number indicating a genome coordinate from a number indicating the length of a gene.
Primary databases have developed highly structured data file formats that enable the storage of all of these additional data that accompany the otherwise “naked” DNA sequence encoded in a FASTA file. The strict layout is necessary for the file to be compatible with a range of computer programs. Each of the three primary databases have their own sequence file format layout. However, all of them contain almost the same fields and the same information, making them interchangeable. It is worth noting that there are many more file formats that have been customised to serve specific purposes. Those we are going to discuss here store additional information related to DNA and protein sequences. For simplicity, we are going to present the GenBank sequence file format only, but we will discuss the EMBL format in the following activities.
Use this link to GenBank to view an entry for a hypothetical protein from Escherichia coli.
The first part of this GenBank entry is also given below. The screen grab shows various details, the first section includes the entry’s LOCUS, DEFINITION, ACCESSION and VERSION
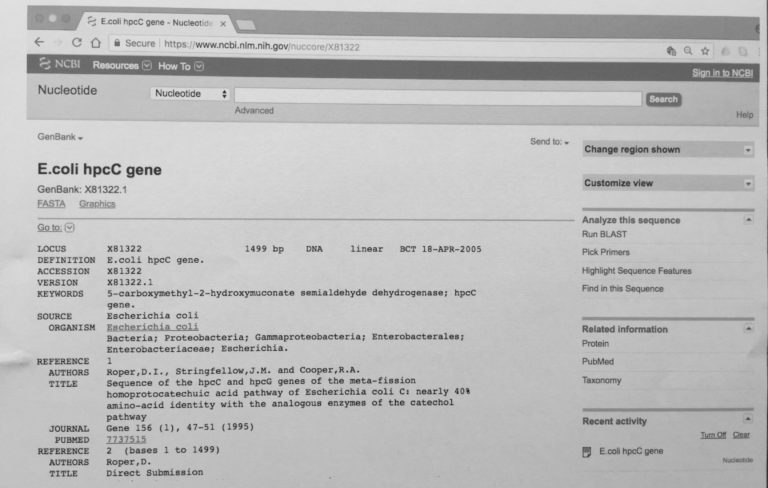 .
.
and denoted by ORIGIN, you can see that the final detail is the actual sequence. These five elements are the essential parts of the GenBank format.
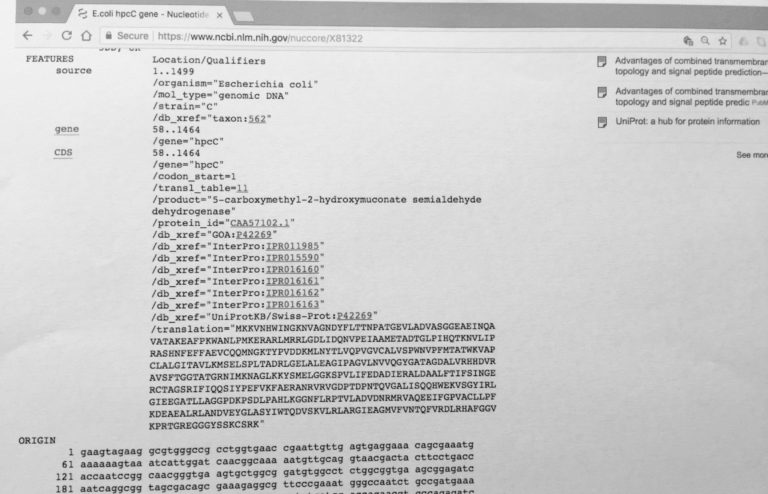
The rest of the sections are added information that, although important, are not essential and could be missing. Note, we could not lack the LOCUS field for a GenBank file, or it could not be recognised as such a file.
The non-essential parts of the entry contain what is commonly known as metadata, and can include more detailed information about the organism, cross-references to other databases, and even a list of publications in which this entry is featured in. The FEATURES part of the entry describes important characteristics of the entry’s sequence such as presence of coding sequences, proteins, etc. This section is less human-friendly, and it may contain fields that do not make any sense to the untrained eye. But don’t worry, this parts are mainly intended to be read by a computer program.
Finally, at the end of the file, we find the actual sequence that could be DNA or protein. Note that the last line of the entry has a “//”. These two characters are very important and indicate the end of the entry/file. Although it might be clear to you that this is the end of the file because there is nothing else underneath, computer programs have to be told when to stop reading.
So within one file, we have a wealth of information, from the nucleotide sequence of the genome to the publications that are related to this genome entry and cross-references to other databases.
Now use this link https://www.ebi.ac.uk/ena/browser/api/embl/X81322.1?download=true to download a file containing the equivalent sequence entry to E.coli X81322 in EMBL format, from the EMBL-EBI ENA database and scroll down to find the end point.
For ease of reference this entry is also presented in 2 parts below. However, unlike the file above, these two screen grabs do not give the endpoint of the entry. .

Part 1: Sequence entry for_E.coli_ X81322 in EMBL format – from the EMBL-EBI ENA database.

Part 2: Sequence entry for_E.coli_ X81322 in EMBL format, from the EMBL-EBI ENA database.
Identify the main differences between the first, GenBank entry and the other sequence entry, for_E.coli_ X81322 in EMBL format that you have studied?
Share your findings with your fellow learners in the comments area.
Think about why there are these differences, and share your thoughts on this with others.
Bacterial Genomes I: From DNA to Protein Function Using Bioinformatics


Bacterial Genomes I: From DNA to Protein Function Using Bioinformatics
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




