
DNA is the Code For Life
What is the genome?
Increasingly clinicians, scientists and even the media, are talking about the genome and the impact of genomic data, now and in the future, on healthcare.
The genome describes an organism’s complete set of genetic instructions. For the human genome this means the ~ 3.2 billion bases which contain the code for ~ 20 000 genes.
What is DNA?
DNA (or deoxyribonucleic acid) is a long molecule that contains our unique genetic code. Like a recipe book, it holds the instructions for making all the proteins in our bodies.
The Double Helix
As famously described by Watson and Crick in 1953, DNA usually exists as two coiled chains, like a twisted ladder. This is called the double helix. The rungs of the ladder consist of nucleotides. Nucleotides are composed of a nitrogenous base, a five-carbon sugar (ribose or deoxyribose), and at least one phosphate group.
The nitrogenous bases are called adenine (A), guanine (G), thymine (T) and cytosine (C). A will always pair with T and C will always pair with G via hydrogen bonds. In this course, to avoid confusion, we use the term “base” rather than “nucleotide”, although the two terms are often used interchangeably.
 Figure 1: Diagram of the double helix Click to expand
Figure 1: Diagram of the double helix Click to expand
© YourGenome
In order that cells can develop, grow and differentiate to fulfill particular roles – such as eye cells, muscle cells, blood cells etc. – they must generate proteins.
DNA is Life
However, it is important to appreciate (and mind-blowing to realise) that the instructions for building proteins and therefore the basis for complex life as we know it, rests with the simple four base DNA code: because each group of three consecutive bases encodes one of 20 amino acids, the basic building blocks of proteins, different combinations of bases result in differently ordered amino acids and different proteins.
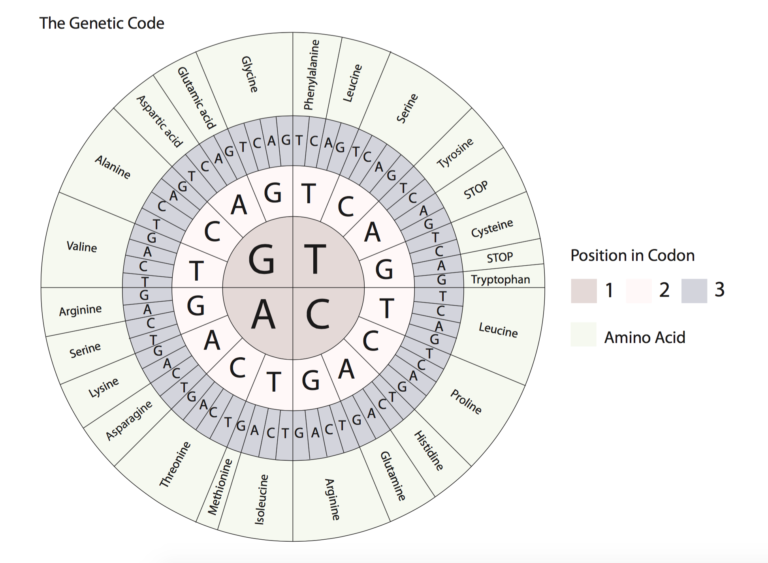 Figure 2: The Genetic Code Click to expand
Figure 2: The Genetic Code Click to expand
© St George’s, University of London
As shown in Figure 2, each amino acid is coded for by a combination of three adjacent nucleotides (A, T, G, C), known as a “codon”.
The Genetic Code
The inner circle represents the first nucleotide of the codon, the ring outside of the centre represents the second nucleotide in the codon, and the ring outside of this represents the third nucleotide in the codon. The outer ring shows either the amino acid coded for by the codon, or the STOP signal. For example, the nucleotide sequence C, A, T from inside to out, codes for the amino acid histidine.
Conditions for DNA to Replicate Itself
Finally, a key feature of DNA and fundamental to its ability to faithfully replicate itself, encode proteins and the basis to modern techniques to decipher the genome is the fact that the two chains of the double helix will only fit together correctly if the A is opposite T and C is opposite G.
One strand of the DNA will, therefore, act as a template for the synthesis of an exact replica of the opposite strand. As Watson and Crick famously said, “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material….”
Just for Fun: Amino Acids Message
Amino acids are often abbreviated to three letter codes in genetic reports. In the past, a single letter code for amino acids was also used. The single letter code is rarely used today, but you may see it in older literature.
This table gives the three letter and single letter codes for the amino acids.
Using the table and the genetic code image in Figure 2 above, can you decode the following message and respond appropriately?
TGG CGT ATT ACC GAG GCC ATG GAA TCT TCA GCT GGG GAA
Answer
Check out the answer to the above “just for fun” activity here.
The Genomics Era: the Future of Genetics in Medicine


The Genomics Era: the Future of Genetics in Medicine
Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




