
Shared Memory Architecture

The fundamental feature of a shared-memory computer is that all the CPU-cores are connected to the same piece of memory.
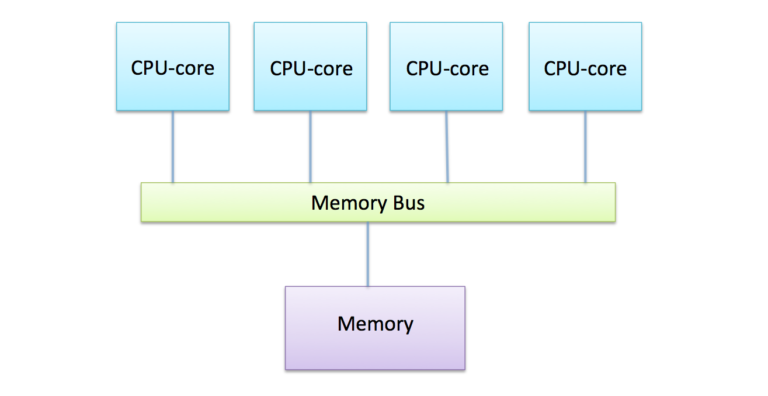
This is achieved by having a memory bus that takes requests for data from multiple sources (here, each of the four separate CPU-cores) and fetches the data from a single piece of memory. The term bus apparently comes from the Latin omnibus meaning for all, indicating that it is a single resource shared by many CPU-cores.
This is the basic architecture of a modern mobile phone, laptop or desktop PC. If you buy a system with a quad core processor and 4 GBytes of RAM, each of the 4 CPU-cores will be connected to the same 4 Gbytes of RAM, and they’ll therefore have to play nicely and share the memory fairly between each other.
A good analogy here is to think of four office-mates or workers (the CPU-cores) sharing a single office (the computer) with a single whiteboard (the memory). Each worker has their own set of whiteboard pens and an eraser, but they are not allowed to talk to each other: they can only communicate by writing to and reading from the whiteboard.
Later on, we’ll start to think about how we can use this shared whiteboard to get the four workers to cooperate to solve the same problem more quickly than they can do it alone. However, the analogy already illustrates two key limitations of this approach:
-
memory capacity: there is a limit to the size of the whiteboard that you can fit into an office, i.e. there is a limit to the amount of memory you can put into a single shared-memory computer;
-
memory access speed: imagine that there were ten people in the same office – although they can in principle all read and write to the whiteboard, there’s simply not enough room for more than around four of them to do so at the same time as they start to get in each other’s way. Although you can fill the office full of more and more workers, their productivity will stall after about 4 workers because the additional workers will spend more and more time idle as they have to queue up to access the shared whiteboard.
Limitations
It turns out that memory access speed is a real issue in shared-memory machines. If you look at the processor diagram above, you’ll see that all the CPU-cores share the same bus: the connection between the bus and the memory eventually becomes a bottleneck and there is simply no point in adding additional CPU-cores. Coupled with the fact that the kinds of programs we run on supercomputers tend to read and write large quantities of data, it is often memory access speed that is the limiting factor controlling how fast we can do a calculation, not the floating-point performance of the CPU-cores.
There are various tricks to overcoming these two issues, but the overcrowded office clearly illustrates the fundamental challenges of this approach if we require many hundreds of thousands of CPU-cores.
Despite its limitations, shared memory architectures are universal in modern processors. What do you think the advantages are?
Think of owning one quad-core laptop compared to two dual-core laptops – which is more useful to you and why?
Share and discuss your ideas with your fellow learners!


Reach your personal and professional goals
Unlock access to hundreds of expert online courses and degrees from top universities and educators to gain accredited qualifications and professional CV-building certificates.
Join over 18 million learners to launch, switch or build upon your career, all at your own pace, across a wide range of topic areas.




